Wanted to highlight some awesome work done by Vedant Puri et al. in collaboration with camfer!
FLARE is a novel self-attention mechanism that learns a low-rank token mixing mechanism by routing attention through fixed-length latent sequences. This reduces the attention-block time complexity to linear scale, meaning we can learn on long sequences like point clouds!
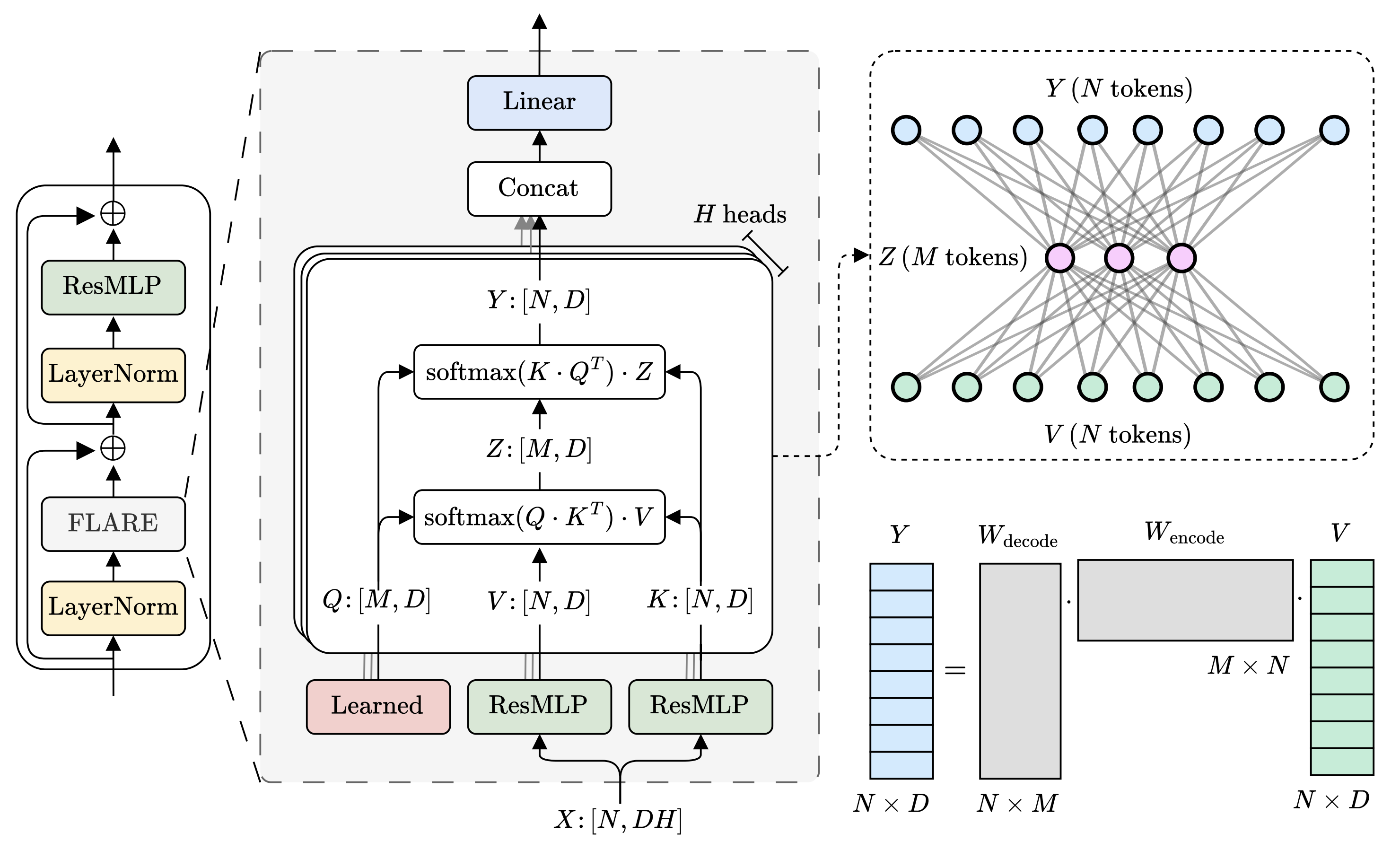
FLARE can be implemented with standard SDPA kernels and scales to meshes with one million points (over 200× faster than vanilla attention!). In torch, this is as simple as:
import torch.nn.functional as F
def flare_multihead_mixer(q, k, v):
"""
Arguments:
q: Query tensor [H, M, D]
k: Key tensor [B, H, N, D]
v: Value tensor [B, H, N, D]
Returns:
y: Output tensor [B, H, N, D]
"""
z = F.scaled_dot_product_attention(q, k, v, scale=1.0)
y = F.scaled_dot_product_attention(k, q, z, scale=1.0)
return yBy projecting the input sequence of length N, then unprojecting back up, we get a low-rank form of attention with rank at most M. And since FLARE allocates a distinct slice of the latent tokens to each head, we get num_heads distinct projection matrices that can specialize in their routing patterns.
We’re excited to see how models built on FLARE perform when applied to downstream tasks, such as generating embeddings for LLM point-cloud understanding.
Code can be found at https://github.com/vpuri3/FLARE.py.
If this line of work is interesting, please reach out directly to hiring@camfer.dev! Or see open roles here!